I’ve always been one of those writers who pays careful attention to reviews of my books. It comes at an emotional cost — it’s never easy to read a very critical review. But I believe the feedback is useful both from a writing perspective as well as the impact on sales. I did a second proofreading pass on Avogadro Corp in response to reviews, and then years later even did a full rewrite, and both revisions saw an increase in the average rating and an increase in the sell-through rate to the sequel. Although I think of writing as an art, it’s an art that helps pay the bills, and I like that. It’s good business to pay attention to your customers (in this case, readers) and what they want.
I knew that Kill Switch would be different because I was writing about topics that would alienate some of my core fans: relationships, sexuality, polyamory, kink, and homosexuality. As I wrote about in the afterword, I chose those topics with intention. In part, I wanted to destigmatize those topics by writing about them in an accurate, non-titillating way, to help out people who are currently marginalized. I wanted to challenge readers to think about and possibly accept people that they might not otherwise. And most importantly, and core to the kinds of topics I normally write about, I wanted to draw connections between privacy, risk, and personal freedom, and those topics made for a rich way to explore those threads.
I expected some readers would object, and they did. Sometimes those objections came with direct honesty, such as the person who messaged me that they were an older white male and didn’t want to read about lesbians having sex. Other reviews and messages said that the first half of the book was a little slow and bogged down with relationship and sexual stuff, but that the second half of the book was very fast paced — which I think is a fair and legitimate observation. Many of those latter readers remarked that they were glad they finished, and they ultimately saw the connections I was trying to draw.
But recently there have been several reviews and messages from people saying they didn’t enjoy the book, and it wasn’t the polyamory, kink, or lesbians they were objecting to, but that the book was about relationships. They wanted a technothriller and didn’t feel that Kill Switch delivered on that promise. A few even said they wanted their money back. To me, this feedback feels a lot more critical. If I under-delivered on the story and the tech, that’s an issue I would want to address. I’d also be pretty disappointed in myself if I failed to deliver on that.
I decided to investigate what portion of the book was spent on the tech plot versus the relationships and kink. I went through the chapters, categorizing each as a relationship/kink chapter or a tech chapter or mixed, and listing the word count. The mixed chapters tended to be mostly tech rather than relationship, but for the sake of simplicity, I counted them as 50% tech and 50% relationship, and divided up the word count.
What I found is that there are 105,000 words of tech plot line, and 33,700 of relationship/kink. That breaks down to 76% tech, and 24% relationship/kink. The first half of the book is heavy on relationship stuff (64% tech to 36% relationship), whereas the second half of the book is overwhelming tech (92% tech to 8% relationship.) Further breaking down the relationship/kink/sex scenes, it turns out to be 22,000 words on relationships and 11,700 words on BDSM play (e.g. 16% of the book is about relationships, and 9% about sex.)
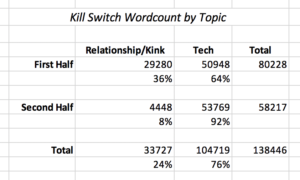
Breakdown of word count by topic in Kill Switch
If I was to make a change based solely on those reviews, it would be to cut the amount of relationship/kink in the first third of the book, which is where I’m guessing people are getting bogged down. In the back of my mind, I started to think about making another editing pass, thinning out those topics, even though it might weaken some of the points I was trying to get across. But then I made a surprising discovery…
There’s a very significant bias depending on where the reviews are posted!
- On Amazon, Kill Switch appears to be deeply polarizing: there are 22 reviews, with 59% being positive (5 stars), and 41% being negative (1 or 2 stars). There is no middle ground: there are no 3 or 4 star reviews.
- On Goodreads, where there are 62 ratings, there are 76% positive reviews (4 or 5 stars), 17% neutral reviews (3 stars), and only 4% negative reviews (1 or 2). These ratings are very similar to Kill Process, which is 79% positive and 4% negative.
If the writing and story in Kill Switch were deeply flawed, I think I’d see reviews on Goodreads that were more closely aligned with what’s on Amazon. Readers want a good story, and they aren’t going to give good reviews if the story is missing. Based on the word count analysis, I think that story is there: there’s 105,000 words of solid tech plot line. By comparison, my first two novels were under 80,000 words, which means that Kill Switch delivers 25% more tech than those first books.
My working assumption at this point is that a portion of the people who gave negative reviews to Kill Switch were in fact struggling with their acceptance of the more controversial poly/kink/homosexuality topics (whether they were aware of it or not), and they may have couched those feelings in more neutral ways by talking about relationships vs tech plot.
Although I find those negative reviews on Amazon very discouraging, at this time I’m inclined to just leave the book be and hope that eventually it finds an audience on Amazon that resonates more strongly with it, as it clearly has on Goodreads.
In the meantime, there have been some reviewers that have really enjoyed Kill Switch and believe it’s the best novel yet. I really appreciate your encouragement, which makes all the work of writing worthwhile! Thank you so much.